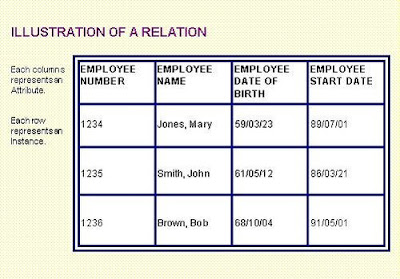
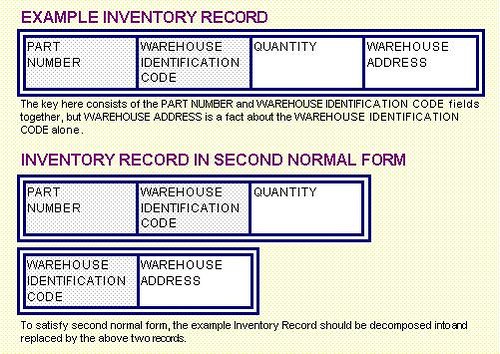
An Overview of Database Management Systems
There are two approaches to data storage:
File-Based Approaches
File-based approaches to data storage are based on relatively simple data structures, such as the Indexed Sequential Access Method (ISAM), and are usually implemented for a single application.
Files are generally created on an as needed basis to service the data needs of an application. The files are associated with an application. The same data may be repeated on many files and stored under different names. For example, an accounting application may refer to customer name while a purchasing application may refer to buyer name. The physical storage characteristics of the same data may be different for different applications. For example, one application may allow 20 characters for name while another application allows 25 characters for the same name. Different business units are responsible for different data.
Disadvantages of a File-Based Approach
Updates to files may result in inconsistent data across the organization. For example, if an accounting application updates a customer name without notifying other application areas that also maintain customer name, customer name will be stored differently for different applications.
A file-based data storage approach makes it difficult for other applications to access data not owned by their application. Data owned by other applications may be stored in a format not consistent with the retrieval capabilities of another application.
File-based approaches to data storage are tied to applications rather than the entities to which the files refer. File-based approaches do not recognize relationships between entities until such information is needed by an application.
Database Approaches
Database approaches to data storage support the sharing of data across multiple applications with multiple users. Databases are structured in a way that is meaningful to an organization. For example, if an organization maintains information on suppliers and the geographic areas they service, there would be a link in the database between the suppliers and geographic areas. Databases reduce data redundancy.
A Database Management System (DBMS) is the software that handles all database accesses. A DBMS presents a logical view of the data to the users. How this data is stored and retrieved is hidden from the users. A DBMS ensures that the data is consistent across the database and controls who can access what data.
Categories of Database Management Systems
The main categories of DBMSs are:
HIERARCHICAL DATABASES
Description of Hierarchical Database
In the hierarchical structure, data is represented by a simple tree structure. The record type at the top of the tree is usually known as the "root." The simple hierarchical structure consists of a root and a single dependent record type. In general, the root may have any number of dependent records, each of which may have any number of lower-level dependents, and so on, to any number of levels.
The hierarchy view contains records of different types connected by links.
Hierarchical relationships of records are explicitly defined in the data structure. A parent record can have many child records but a child record can have only one parent. There are no many-to-many relationships between records. No dependent record within a hierarchical data structure can exist without its parent record. For this reason, records must be seen in context.
Examples of hierarchical DBMSs include IBM's Information Management System (IMS) and System 2000.
Strengths of Hierarchical Databases
The advantages of a hierarchical database are:
· efficient representation of hierarchical structures,
· efficient single key search and access time (if the hierarchical structure corresponds to application views of the data),
· fast update performance where locality of reference exists (locality of reference states that performance is significantly enhanced when the processing is close to the data being processed).
Weaknesses of Hierarchical Databases
The disadvantages of a hierarchical database are:
· lack of flexibility (non-hierarchical relationships are awkward to represent; redundancy may be required),
· poor performance for non-hierarchical accesses,
· lack of maintainability (changing relationships may require physical reorganization of data).
NETWORK DATABASES
Description of Network Database
In a network database structure, data is represented by records and links. There is no limit to the number of immediate parent segments or the number of immediate child segments a given record occurrence may have.
The network database structure allows the modelling of many-to-many relationships.
DMS and IDMS are examples of network databases.
Strengths of Network Databases
The advantages of a network database are:
· efficient representation of some structures (varies widely with physical implementation),
· more flexibility than a hierarchical approach (all relationships can be represented without redundancy).
Weaknesses of Network Databases
The disadvantages of a network database are:
· machine performance (physical implementations that perform well for one type of network may perform poorly for another type),
· maintainability (changing relationships may require physical reorganization of data),
· lack of robustness. A failure in the system can leave dangling references to data which must somehow be recovered,
· update overheads in multi‑key databases.
RELATIONAL DATABASES
The relational model for databases provides the basic DBMS characteristics. In addition, an RDBMS also conforms to Codd's model.
Relational Database Characteristics
Dr. Codd established 12 rules to which a DBMS must conform to be considered relational. DBMSs vary in the way in which they comply with these rules, however, commercial relational databases generally conform to these rules.
Strengths of RDBMS
Flexible and well-established.
Sound theoretical foundation and use over many years has resulted in stable, standardized products available.
Standard data access language through SQL.
Costs and risks associated with large development efforts and with large databases are well understood.
The fundamental structure, i.e., a table, is easily understood and the design and normalization process is well defined.
Weaknesses of RDBMS
Performance problems associated with re-assembling simple data structures into their more complicated real-world representations.
Lack of support for complex base types, e.g., drawings.
SQL is limited when accessing complex data.
Knowledge of the database structure is required to create ad hoc queries.
Locking mechanisms defined by RDBMSs do not allow design transactions to be supported, e.g., the "check in" and "check out" type of feature that would allow an engineer to modify a drawing over the course of several working days.
OBJECT DATABASES
With the increased awareness of the object-oriented paradigm, many DBMSs claim to be object-oriented databases.
The object-oriented model provides the basic DBMS characteristics. In addition Object-oriented Database Management Systems provide the following features.
Mandatory
· Support for Complex Objects
An ODBMS must provide support for data types that allow storage of complex objects. An RDBMS supports only basic types, (e.g., integer, character), that are assembled into table rows to define objects.
· Identity
An object must be uniquely identified.
· Encapsulation
Hiding information and only allowing access through the public interface is a basic concept in object-orientation. Strict implementations enforce access to data through programs, however, some ODBMS products allow query access to the data.
· Classes and Types
An ODBMS must allow definition of classes and data types by the user. In addition these must not be restricted by the implementation. User defined types must be treated the same as the product supplier's base types in the database functionality.
· Inheritance
Inheritance is a basic concept in object-orientation that is a major factor in re-use. Inheritance of data and methods is a primary feature of an object-oriented programming language (OOPL).
· Dynamic Binding and Polymorphism
This characteristic allows different implementations of semantically similar methods with the same name in different classes.
· Computational Completeness
The integrated language must be computationally complete.
For example, SQL is relationally complete since a SELECT statement can be constructed to retrieve any subset of data within an RDBMS. SQL is not computationally complete (it is sometimes called a data sublanguage) since there are computations that cannot be done using SQL constructs. The ODBMS language cannot have this restriction.
· Extensibility
The user must be able to add non-restricted types to the database.
Strengths of ODBMS
Representations of complex structures allow creation of a model that more closely resembles its real world counterpart.
Storage of complex objects results in better performance.
The model exhibits better coupling and cohesion characteristics. This results in a more maintainable and flexible database.
Weaknesses of ODBMS
Lack of maturity in the products. This leads to more risk in employing the product. There is also a lack of product standardization. Database standards are emerging.
There is no equivalent of SQL for object-oriented databases. Work is being done on establishing standards.
There is much less experience with project development. Hence, there is a lack of information on costs and schedules. In addition, there is added training required for the team because of the lack of familiarity with the object paradigm.
There is no consistent, solid theoretical basis to support ODBMS products. This raises questions about the completeness of the implementations. In addition, there is a plethora of analysis and design approaches.
Selecting a Database
Database technology may not always be needed, depending on the sophistication of the system's data structures, complexity of data, and the need for features provided by databases.
In selecting a database, it is important to consider, in addition to the actual data management capabilities, the extent of the development environment provided or supported. Since the physical view of data can be separated from the application view, the development environment provided or supported will have a significant effect on the ability to generate new applications or maintain existing applications using this data. Application engineers and developers do not need to know about the storage structure or access strategy of data to develop or modify applications.
Support for a standard query language, such as SQL, is also an important criteria. By developing applications using a standard query language, flexibility is achieved since the underlying database product can be changed or modified without necessarily affecting the applications that access the data. Note, however, that some DBMSs have added functionality not supported by the standard query language. Use the added functionality with caution.
There are also many other criteria to consider when selecting a database which I will cover in later posts.